ADP 24회 실기 문제#
Attention
1번
데이터 확인 및 전처리
1.1 데이터 EDA 및 시각화
1.2 결측치 처리 및 변화 시각화, 추가 전처리가 필요하다면 이유와 기대효과를 설명하라
1.3 결석일수 예측모델을 2개 제시하고 선택한 근거 설명
1.4 선정한 모델 2가지 생성 및 모델의 평가 기준을 선정하고 선정 이유 설명
1.5 모델이 다양한 일상 상황에서도 잘 동작한다는 것을 설명하고 시각화 하라
1.6 모델 최적화 방안에 대해 구체적으로 설명하라
데이터 설명
성별(sex) 바이너리 : ‘F’ - 여성 또는 ‘M’ - 남성
나이(age) 숫자: 15 - 22
부모님동거여부 (Pstatus) 바이너리: T: 동거 또는 ‘A’: 별거
엄마학력(Medu) 숫자 : 0 : 없음, 1 : 초등 교육, 2 : 5-9학년, 3 - 중등 교육 또는 4 - 고등 교육
아빠학력(Fedu) 숫자 : 0 : 없음, 1 : 초등 교육, 2 : 5-9학년, 3 - 중등 교육 또는 4 - 고등 교육
주보호자(guardian) 명목형 : ‘어머니’, ‘아버지’ 또는 ‘기타’
등하교시간(traveltime) 숫자 : 1 : 15분이하, 2 : 15 ~ 30분, 3 : 30분 ~ 1시간, 4 : 1시간 이상
학습시간(studytime) 숫자 : 1 : 2시간이하, 2 : 2~5시간, 3 : 5~10시간, 4 : 10시간이상
학고횟수(failures) 숫자 : 1, 2, 3 else 4
자유시간(freetime) 숫자 : 1(매우 낮음), 2, 3, 4, 5(매우 높음)
가족관계(famrel) 숫자 : 1(매우 나쁨), 2, 3, 4, 5(우수)
Show code cell source
import pandas as pd
df= pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/adp/24/problem1.csv')
df.head()
| sex | age | Pstatus | Fedu | Medu | guardian | studytime | traveltime | failures | famrel | freetime | absences | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | F | 18.0 | A | 4 | 4 | mother | 2 | 2.0 | 0 | 4 | 3.0 | 6 |
| 1 | F | 17.0 | T | 1 | 1 | father | 2 | 1.0 | 0 | 5 | 3.0 | 4 |
| 2 | F | 15.0 | T | 1 | 1 | mother | 2 | 1.0 | 3 | 4 | 3.0 | 10 |
| 3 | F | 15.0 | T | 2 | 4 | mother | 3 | 1.0 | 0 | 3 | 2.0 | 2 |
| 4 | F | NaN | T | 3 | 3 | father | 2 | 1.0 | 0 | 4 | 3.0 | 4 |
2번
광고횟수와 광고비에 따른 매출액의 데이터이다
2.1 광고비 변수를 가변수 처리후 다중회귀를 수행하여 회귀계수가 유의한지 검정
2.2 회귀식이 유의한지 판단
Show code cell source
import pandas as pd
df= pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/adp/24/problem2.csv',encoding='cp949')
df.head()
| 광고횟수 | 광고비 | 매출액 | |
|---|---|---|---|
| 0 | 2 | 낮음 | 15 |
| 1 | 3 | 낮음 | 16 |
| 2 | 4 | 낮음 | 17 |
| 3 | 4 | 높음 | 18 |
| 4 | 5 | 높음 | 20 |
3번
A생산라인의 제품 평균은 5.7mm이고 표준편차는 0.03, B생산라인의 제품 평균은 5.6mm이고 표준편차는 0.04라면 5%유의수준으로 두 제품의 평균이 차이가 있는지 여부를 검정하기 Z(0.05) = 1.65
3.1 귀무가설과 대립가설을 세워라
3.2 두 평균이 차이가 있는지 검정하라
Show code cell source
###
4번
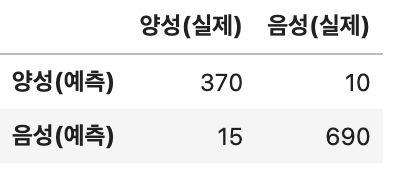
바이러스 감염 분류표를 보고 베이지안 분류 방법을 사용해 양성으로 예측된 사람이 실제로 양성일 확률을 구하라
Show code cell source
###
5번
주어진 데이터에서 신뢰구간을 구하려한다
정규분포에서 표폰을 추출함[Z(0.05) = -1.65 , Z(0.025) = -1.96, T(0.05, 8) = 1.860 , T0.025(0.025, 8) = 2.306]
데이터(9개) : [3.1, 3.3, 3.5, 3.7, 3.9, 4.1, 4.3 4.4, 4.7]
5.1 모분산을 모르는 경우 주어진 데이터의 95% 신뢰구간을 구하라
5.2 sigma = 0.04인걸 알고 있을때의 95% 신뢰구간을 구하라
Show code cell source
###
이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다